When research data and code are open, it benefits the research community and the world. Open data and code is more visible and this enhances its reach and impact for researchers. The best place to make your data or code open is through a data repository. Choosing the right repository for your data is simple but it can be confusing.
Follow this decision tree to decide how to choose a repository for your data and/or code:
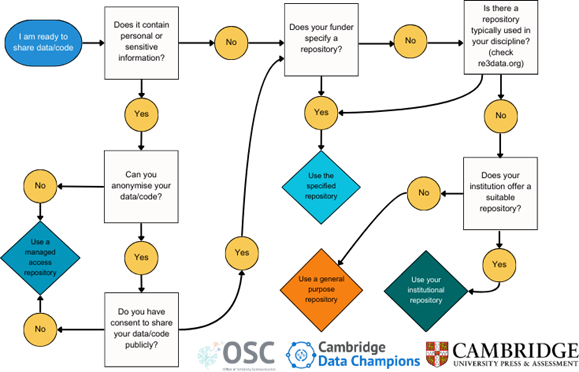
Decision tree
Depending on your funder, your discipline, and your type of data and code, you may have options to choose from.
For data/code that contains personal/sensitive information:
- Anonymise the data/code if possible. If you have consent to share the data/code publicly, follow the guidance below for non-sensitive data/code from 1.
- If the data cannot be anonymised, you will need to use a managed or controlled access repository if possible.
For data that does not contain personal/sensitive information:
- If your funder specifies a repository, deposit your data there
- If your funder does not specify a repository, use a discipline-specific one if available
- If your funder does not specify a repository and a discipline-specific one is not available, and your institution has a suitable repository, use that
- Otherwise, use a general purpose repository.
Below are some additional things to consider when choosing the right repository for your data and code.
Managed access repositories
Some data repositories allow managed (or restricted or controlled) access to sensitive data. They may require registration or an application to access the data.
To identify repositories that provide restricted access:
- read a list of approved protected access repositories (Open Science Framework)
- search re3data.org using the filter “Data access - restricted”.
Funder-specific repositories
Sometimes your funder specifies a data repository. For example, the ESRC (UKRI) expects data resulting from its grants to be deposited on the UK Data Service ReShare repository. Be sure to check the terms of your funding grant to see if a repository is specified, or whether the repository you choose is acceptable.
Discipline-specific repositories
Many disciplines also have dedicated repositories for data and/or code. For example, archaeologists could consider depositing their data with the Archaeology Data Service. Computational biologists could consider depositing their data with an EMBL-EBI data repository.
There may be benefits to using discipline specific repositories. The repository may be better suited to specific data types, formats and volume more common in a field. The repository may also enhance discipline specific discovery. To find a discipline specific repository you can browse www.re3data.org by subject. You could also explore where experts in your field have deposited their data and/or code.
Institutional repositories
Many universities have their own institutional repository. At the University of Cambridge this is Apollo. Members of the University can deposit research data and code here. Apollo preserves data and/or code for the long-term.
Apollo does not accept personal or sensitive data and datasets over 20GB. Deposits larger than 20GB will incur a one-off deposition cost of £4/GB. Find out more about Apollo and learn how to deposit data into the repository.
General purpose repositories
You can also use general purpose repositories such as Figshare and Zenodo for your data and/or code (or other research outputs). Use use re3data.org and fairsharing.org to search for repositories. You can do so by filtering your search by various criteria.
Zenodo
Zenodo is an open-source, open-access, open-data platform for all fields of research. There are no costs to deposit, but total size per record is limited to 50GB. Zenodo issues DOIs, offers versioning, and records can be embargoed (with metadata visible). You can link your GitHub account with Zenodo to automatically archive your repositories via their GitHub integration.
If your data was created at the University of Cambridge you can upload it to the The University of Cambridge Zenodo Community.
Trustworthy repositories
It is important that the repository you choose is trustworthy. For example, look for the CoreTrustSeal certification. This the mark of a trusted repository. Apollo is CoreTrustSeal certified. OpenAire further explains 'How to find a trustworthy repository for your data'.
Advice on deciding where to deposit your data
Here are some general considerations when deciding on where to deposit your data:
- Does your data and/or code contain personal and sensitive data? If so, are you able to anonymise your data and/or code?
- Do you have consent to share your data and/or code to the public?
- Do you need managed access to your data and/or code?
- Are the repository’s terms and conditions acceptable?
- Are the licenses that the repository provides appropriate for your data and/or code?
- Does the repository provide open access to its repository?
- Where will the repository store your data? Some funders specify storing the data only on servers in the UK or EU.
- How long will the repository store your data?
- Does the repository explain how they will preserve the data if it goes out of service at some point in the future?
- Does the repository give your dataset a permanent DOI?
- Does the repository give your dataset adequate machine-readable metadata?